




Člověk z praxe popsal, o čem se jen šuškalo
Než přejdeme k vědě, je tu člověk, který tenhle pocit popsal nedávno na síti X a jehož příspěvek se rychle šířil po internetu dál a dál. Nav Toor je kanadský tvůrce obsahu v oblasti umělé inteligence a praktický průvodce světem AI pro tisíce lidí, kteří ho sledují na platformě X (dříve Twitter) pod přezdívkou @heynavtoor.
Nepíše akademické práce. Nezabývá se vývojem algoritmů. Pohybuje se tam, kde většina z nás. Tedy v každodenní práci s chatboty a AI agenty, v optimalizaci pracovních postupů, v hledání odpovědi na otázku, jak AI skutečně integrovat do běžného pracovního dne, aby výsledky byly co nejlepší.
Mohlo by vás zajímat

A právě on si všiml něčeho, co si v soukromí říkalo čím dál více lidí, ale nikdo to ještě nepojmenoval tak přesně.
„ChatGPT se vám zdá hloupější než dřív. Vaše prompty, které fungovaly, teď produkují horší výsledky. Psaní zní ploše. Samotný internet se zdá, jako by se smršťoval. Každý článek zní stejně. Každý e-mail zní stejně. Každá odpověď zní, jako by ji napsal ten samý hlas. Mysleli jste si, že chybujete vy. Není to vaše chyba,“ uvedl Nav Toor.
Toor na svém účtu na X pokračoval. Internet se plní AI obsahem: blogy, články, recenze, komentáře, příspěvky na sociálních sítích. Firmy s AI prohledávají tento internet, aby trénovaly další generaci svých modelů. Což znamená, že ta příští generace se trénuje na výstupu té současné.
A na konci vlákna Toor napsal větu, která vystihuje celý problém: „Modelový kolaps není technický problém. Je to kulturní problém. To, kvůli čemu stálo za to internet číst, je to, co zmizí jako první.“
Zdroj: AI models collapse when trained on recursively generated data
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the… pic.twitter.com/hJHOMEnpEh
— Nav Toor (@heynavtoor) June 10, 2026
Co říkají výzkumné studie?
Už v roce 2024 publikoval tým výzkumníků z Oxfordu, Cambridge, Imperial College London a University of Toronto studii v prestižním vědeckém časopise Nature. Původně kolovala pod pracovním názvem The Curse of Recursion, tedy Prokletí rekurze.
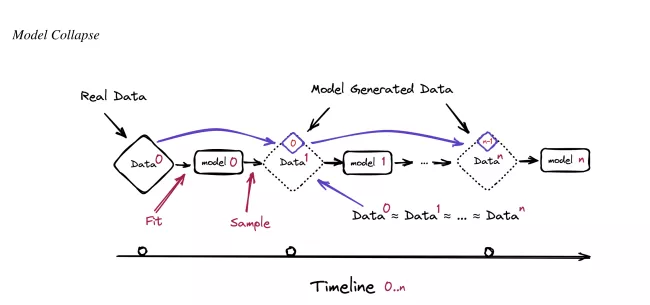
Autoři v ní popsali jev, který nazvali modelový kolaps (Model Collapse): degenerativní proces, při němž AI modely trénované na datech generovaných jinými AI modely postupně zapomínají, jak vypadala původní lidská data.
Mechanismus je v podstatě jednoduchý. AI firmy trénují nové modely tak, že prohledávají internet a stahují obrovské množství textu. Jenže internet se za poslední roky rychle plní obsahem vytvořeným generativní AI. Výsledek? Nová generace modelu se trénuje z velké části na výstupu té předchozí. Každý takový cyklus ztrácí informace. Ne náhodně.
Jako první mizí nejméně obvyklé, nejkreativnější a nejoriginálnější části dat. Ty, kterým vědci říkají „chvosty rozdělení“. Zvláštní nápady, neočekávané pohledy, věci, kvůli kterým byl internet zajímavý ke čtení. Co zbude, je průměr. Bezpečné. Předvídatelné. Nudné. Pak se na tom trénuje další generace, ztrácí víc, trénuje se na zbytku...
Mohlo by vás zajímat

Jak rychle se to děje?
Méně iterací, než by se zdálo. Studie ukázala, že k výraznému zhoršení dochází již po několika málo generacích trénování. Výzkumníci testovali jazykové modely (LLM), generátory obrázků (variační autoencodery, VAE) i statistické modely (Gaussovy směsné modely, GMM).
Vzorec byl vždy stejný: výstup modelů se smršťoval do úzké, zploštělé verze reality, která neměla s původními daty téměř nic společného.
Zajímavý byl i pokus o záchranu. Co kdyby se do každé tréninkové generace přimíchalo alespoň deset procent původních lidských dat? Kolaps byl pomalejší, ale k výraznému zhoršení přesto došlo.
Jedinou věcí, která kolapsu plně brání, je trénování výhradně na lidmi vytvořeném obsahu. A právě toho začíná být na internetu čím dál méně. Někteří odborníci odhadovali, že se kvalitní lidský obsah na webu začne vyčerpávat právě kolem roku 2026.
Mohlo by vás zajímat

Oheň, který znečišťuje prostředí
Ross Anderson, profesor na Cambridge a spoluautor studie, použil přirovnání, které se dostalo do široké diskuse: „Velké jazykové modely jsou jako oheň. Užitečný nástroj. Ale takový, který znečišťuje prostředí.“
Tím znečištěním je AI obsah na internetu. Je neviditelný, bez označení, nerozeznatelný od textu psaného lidmi. A každý AI model, který se právě trénuje na datech z webu, ho nekontrolovaně vstřebává.
Záludnost spočívá v tom, že kontaminace je opravdu neviditelná. Člověk nedokáže spolehlivě poznat, jestli konkrétní věta na internetu pochází od člověka, nebo ji vygenerovala AI. A stejně tak to nedokáže rozlišit AI, která se na tom textu trénuje. Jakmile originální data zmizí, nelze je obnovit. Škoda je nevratná.
Výzkumníci to přirovnávají k ještě jiné analogii: čistá před-AI data jsou jako ocel vyrobená před začátkem jaderných testů v roce 1945. Ta historická ocel neobsahuje radionuklidy a je nenahraditelná pro citlivá vědecká a lékařská zařízení. Stejně tak obsah napsaný lidmi před nástupem ChatGPT má pro trénink AI jedinečnou a čím dál vzácnější hodnotu.
Mohlo by vás zajímat

Je to tedy ChatGPT, nebo my?
Zde je třeba být opatrný. Firmy jako OpenAI, Google nebo Anthropic si riziko modelového kolapsu uvědomují a aktivně pracují na tom, aby se tréninková data nekontaminovala.
Mají k tomu nástroje: přístup k proprietárním datovým sadám, dohody s vydavateli obsahu, filtrování webu. OpenAI například uzavřelo licenční smlouvy s řadou mediálních organizací právě proto, aby mělo přístup k ověřeně lidskému obsahu.
Zároveň ale platí, že internet jako celek se mění rychle a žádná firma nemá dokonalý filtr. Subjektivní pocit, že chatboti odpovídají nějak uniformněji, může mít více příčin najednou. Jednou z nich je záměrné „krocení“ modelů pomocí zpětné vazby od lidských hodnotitelů, kteří odměňují bezpečné, neutrální odpovědi.
Mohlo by vás zajímat
Sedm prstenů, které překládají znakovou řeč, aneb jedno z nejúžasnějších využití umělé inteligence
Novinky

Druhou je právě to, o čem mluví Toor i vědecká literatura: čím více lidí píše s pomocí AI, tím více obsahu na internetu zní podobně, a tím méně rozmanitý materiál pro další trénink zbývá. Modelový kolaps nemusí být jedinou příčinou zhoršeného pocitu z AI, ale věda říká, že jde o reálné riziko.
Pro každodenního uživatele AI nástrojů z toho plyne jedno praktické ponaučení. Originální, specifický a osobní obsah má čím dál větší hodnotu. Přesně ten druh textu, který AI nedokáže snadno napodobit, protože ho na internetu moc nezbývá.
Internet, který nás bavil a překvapoval, byl postavený na tom, že ho psali lidé. Podivní, osobití, nedokonalí, živí lidé. Pokud chceme, aby byl web dál místem, kde se dá něco dozvědět, pobavit se nebo nechat překvapit, bude záležet na tom, jestli v něm pro ty hlasy zůstane místo.
Zdroj: X, Cornell University, Nature, The curse of recursion